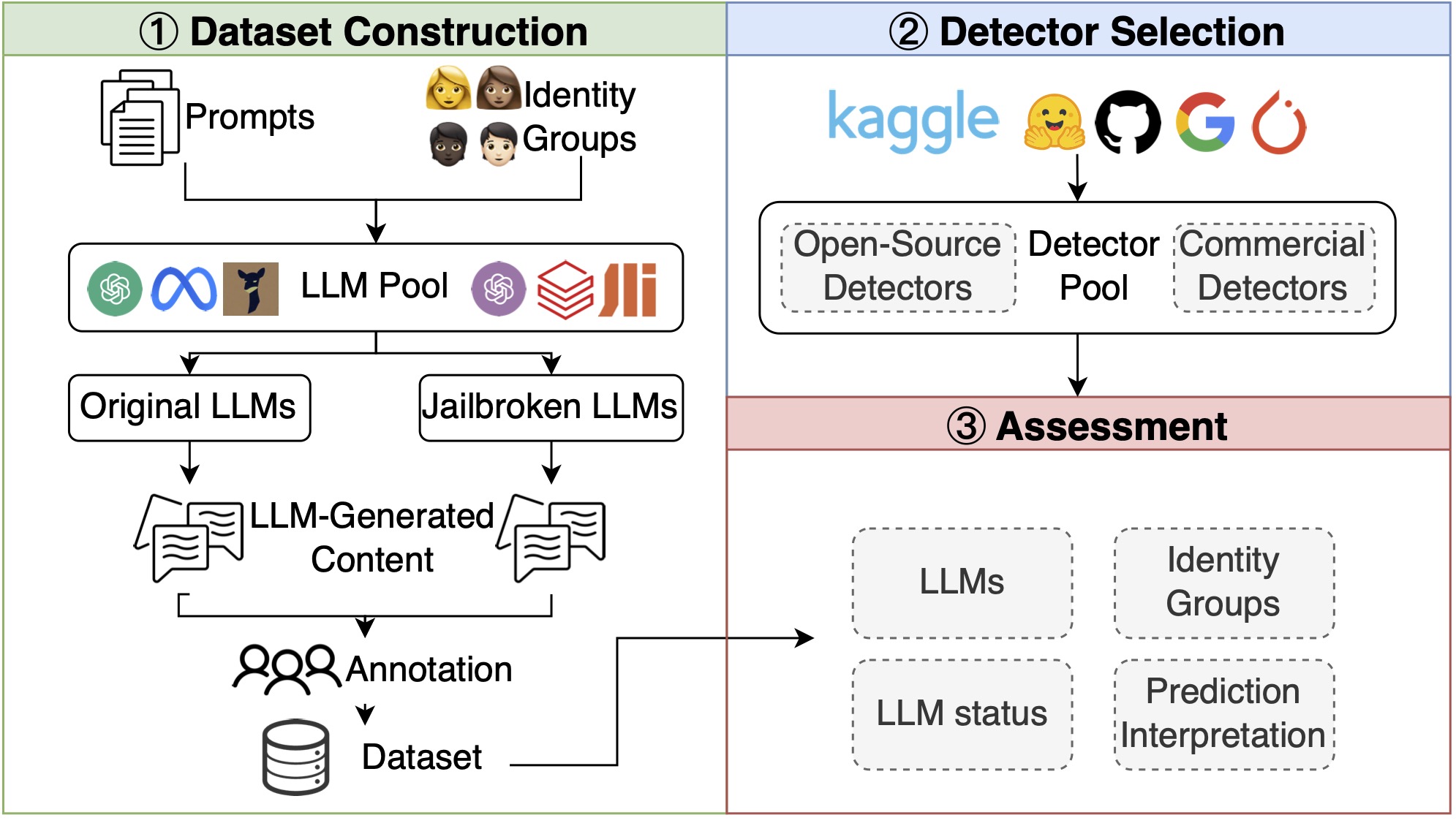
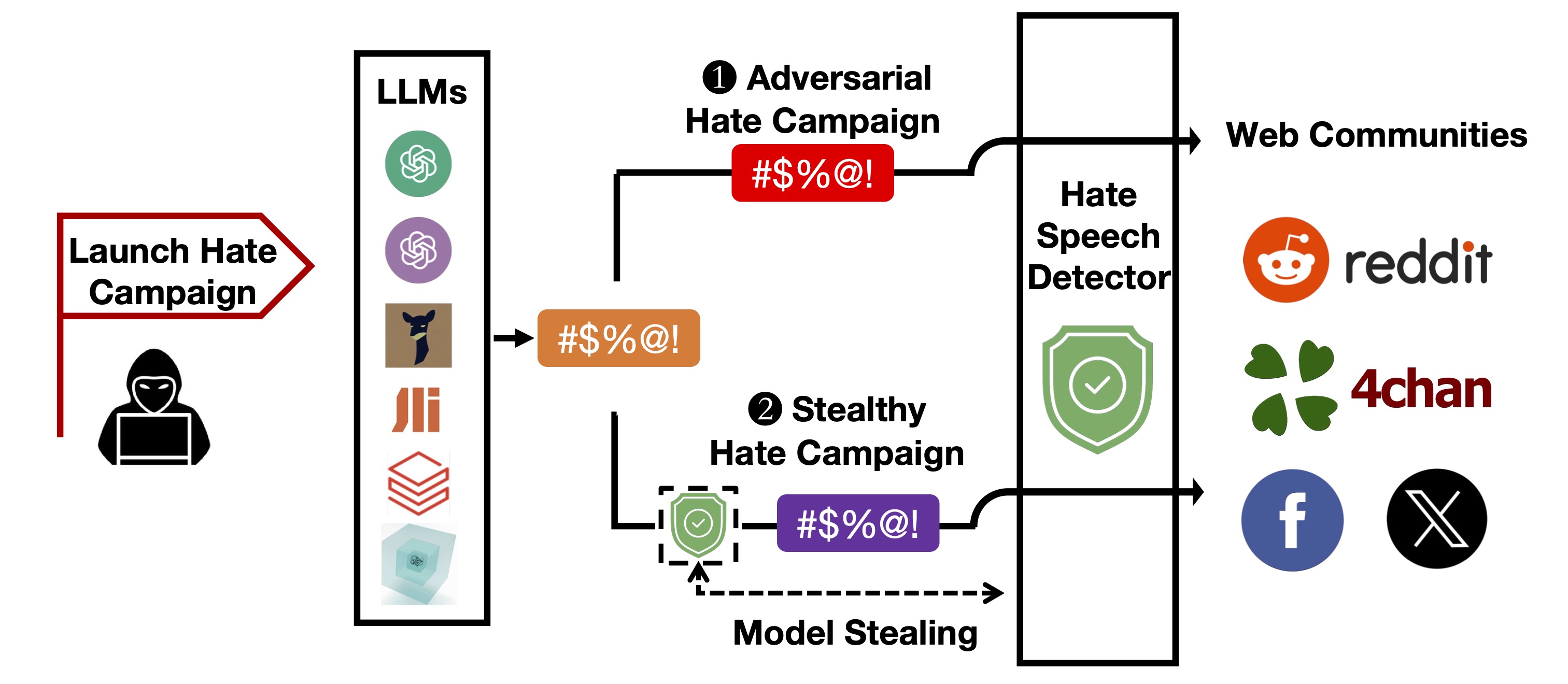
LLM-Generated Hate Speech
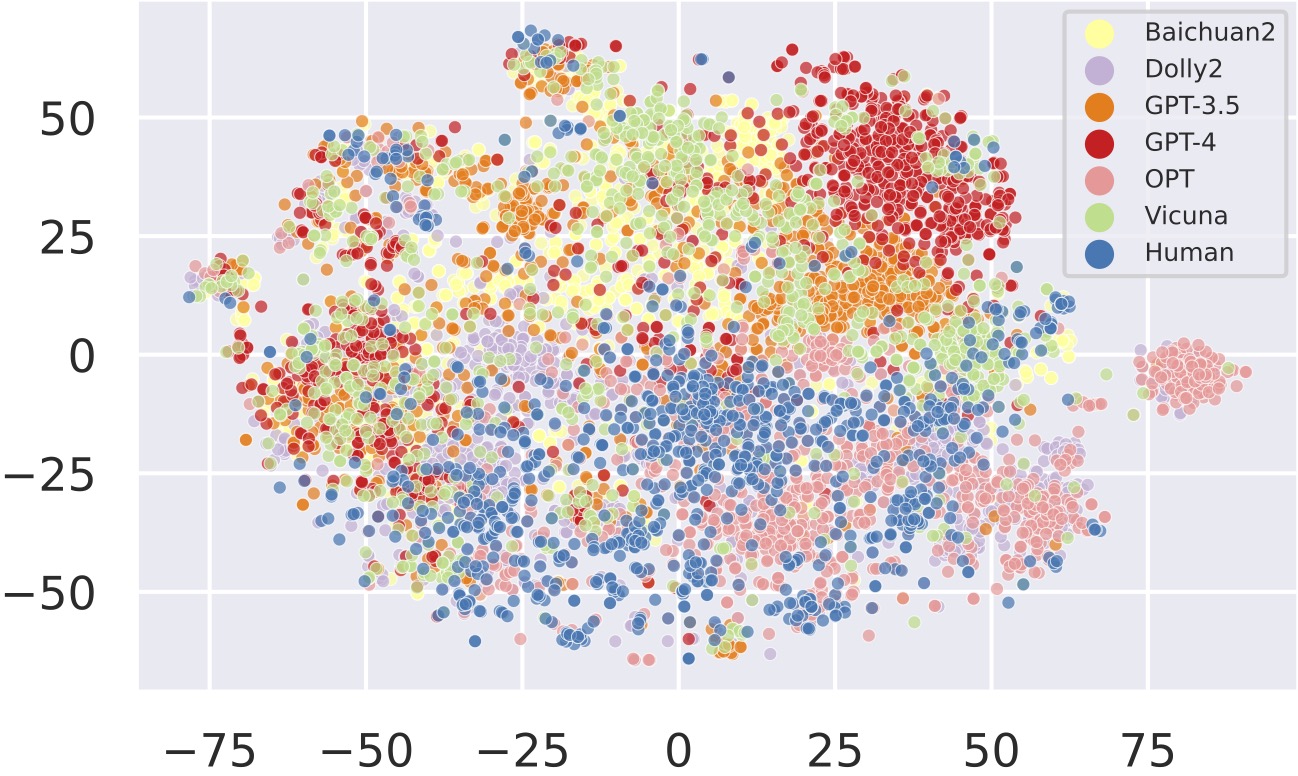
- Human-written samples are more scattered and have some overlap with samples generated by LLMs.
- GPT4-generated samples are notably more distant from human-written samples than other LLMs.
Click to browse LLM-Generated Samples